缓存优化策略
随着数据量的不断累积,存储和查询数据的成本日益增加,在提升系统性能的同时降低维护成本,就需要考虑缓存优化策略了。缓存优化主要涉及两个方面:==存储和耗时==。
问题与难点
缓存优化的目的主要是降低存储消耗,提高读取效率,保证系统的稳定性和数据的准确性。宏观上选择合适的缓存架构,微观上利用高效的压缩技术以及针对性的存储结构。
缓存穿透:查询一个一定不存在的数据,因为缓存中也无该数据的信息,则会直接去数据库进行查询,从系统层面来看像是穿透了缓存层直接达到数据库。
缓存雪崩:如果所有的缓存的失效时间相同,机器宕机,同一时间将有大量请求访问数据库或者重新拉取缓存,导致系统崩溃。
缓存击穿:热点数据在同一时刻失效,大量访问该热点数据的请求将直接访问数据库引起系统崩溃。击穿与雪崩的区别即在于击穿是对于特定的热点数据来说,而雪崩是全部数据。
- 如何存储 数据不能随意存储,不然会造成数据冗余,读取和维护不方便等不利结果,需要考虑数据的类型(纯文本,值类型…)、数据的结构(List,Set,Array…)、业务特性(有效性,相似性,关联性…)
- 如何读取 数据读取需要考虑读取次数、每次读取的数据量、序列化反序列化方式、压缩方式…
- 如何加载 为保证应用启动后能正常提供服务,需要提前加载数据,这时需要考虑如何加载、更新、删除数据…
优化策略
缓存架构
本地缓存: 是程序在同一服务器内的缓存,使用该缓存的优点是数据读取最快,缺点是占用服务器内存、多机冗余、数据不同步等;
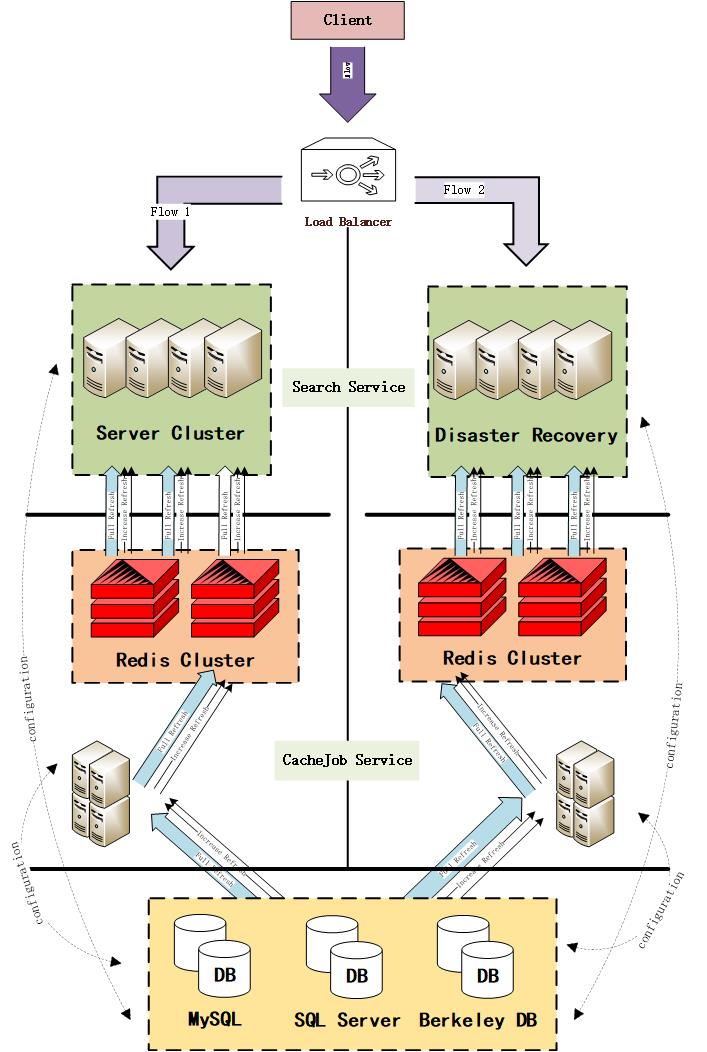
分布式缓存(Redis): 存在数据读取的网络延迟,有更强的一致性,适合作为大规模缓存方案;
考虑到数据业务特性的不同,需要利用不同的缓存技术来存储数据,例如不频繁更新复用率高且量不大的数据(配置信息)可存储在本地缓存中,提高读取速率同时降低服务器集群内数据不一致性带来的影响;数据量大且更新频繁的数据(价格,状态,数量)适合存储在分布式缓存中,维护方便也可保证数据的一致性。
全量: 在提供服务前,需要加载批量数据避免冷启动带来的系统不稳定,这些数据可能是全部的有效数据,也可能是热点数据(命中率较高)。全量加载数据是为了在接入大量请求时,能覆盖大部分的数据需求,避免缓存雪崩。
增量: 全量数据加载需要耗费大量CPU和网络资源,并且不能在短时间能完成,所以数据的增删改应该在全量的基础上进行,从而实时的小批量的数据更新。
全量加载数据的周期应和应用发布周期一致,尽可能减少大批量数据导入带来的系统不稳定,应用提供服务期间通过增量来实时更新数据。全量拉取数据需要考虑每次拉取数据的SIZE,每次读取的SIZE小必将增加读取和处理次数;每次读取的SIZE过大则将导致读取超时,阻塞数据拉取,同时增加序列化反序列化压力。全量需要考虑数据分包问题,将每次拉取的SIZE控制在合适的范围,提高拉取速度;增量采用主动更新的策略,根据数据的变更频率设置合适的刷新周期。如果数据实体中有日期字段可以通过该字段来判断数据实体的时效性,若失效便可剔除。
缓存灾备(异地多活): 为提高系统的可靠性,有必要将缓存数据重新备份,一方面在缓存故障时,提供紧急服务;另一方面在访问增加时,临时提供数据。
数据存储
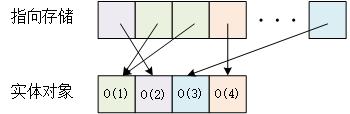
- 数据类型和数据结构的优化 如果数据是布尔类型,有限范围的值类型,可以考虑用==位图==来存储,用少量的bit位来存储原类型数据;如果数据存在相似的结构,可以考虑用==指向存储==,就像对象的赋值一样,变量名只存储对象实体的引用,不同的变量名指向相同的实体。
- 数据的业务特性 将相关联的数据存储到一起,以便在需要时可以一次性将数据全部获得而不用重复读取缓存。另外将==规则和规则明细==分开存储,先判断是否符合规则,只有符合的时候才读取明细,避免读取冗余数据。==动态数据与静态数据==分离,动态数据是参与排序,删选,计算的数据,静态数据则是一些纯文本信息,物理特性,很少变动,直到最后才进行映射输出。
- 数据的有效性 业务请求讲究连贯性,若数据不完整或者数据前后无关联,这类数据不会被访问或者请求无法获得有效响应,可以清理这些数据或者不将其拉入缓存中。数据有生效范围,比如优惠券、活动等时间一过便不可能再被访问,就需要及时剔除,避免占存和不必要的查询;数据的命中率,有些数据经常被访问,有些数据则很少甚至从来没有被访问过,可以考虑存储在不同级的缓存中。
- 数据的过期时间 – 缓存雪崩 应错开数据的过期时间,避免同一时刻大量数据失效进而需要消耗过多网络资源和CPU资源来重建数据。
- 热点数据的缓存策略 – 缓存击穿 将经常被访问的热点数据放在本地,并设置更新策略如LRU算法等
读取效率
-
业务过滤及布隆过滤器 – 缓存穿透 在读取数据前,查看数据时候是有条件的,只有符合条件才会有数据,此类数据的读取可以先判断是否满足条件进而读取数据,避免读取空数据,白白增加耗时。若无法通过业务判断是否有数据,也可通过设计布隆过滤器来进行拦截,避免不必要的数据读取。
-
空数据的读取 – 缓存穿透 读取数据时有时会将数据缓存在本地内存中,以便之后复用,若读取到了空数据,可以存储为空对象,而不是单纯的空或者不存,会导致判空后重复读取分布式缓存。而存储为空对象后,则知道已经读取过,只是值为空罢了,没必要再次读取。但空对象需要及时清理,避免长时间占据内存。
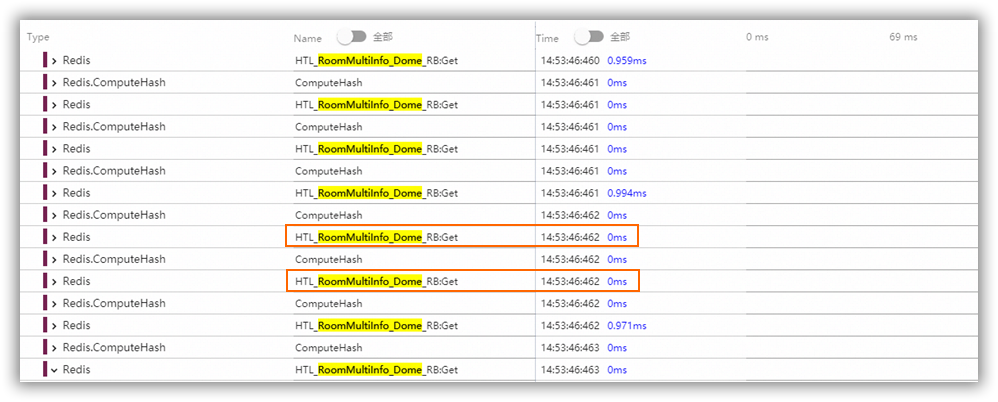
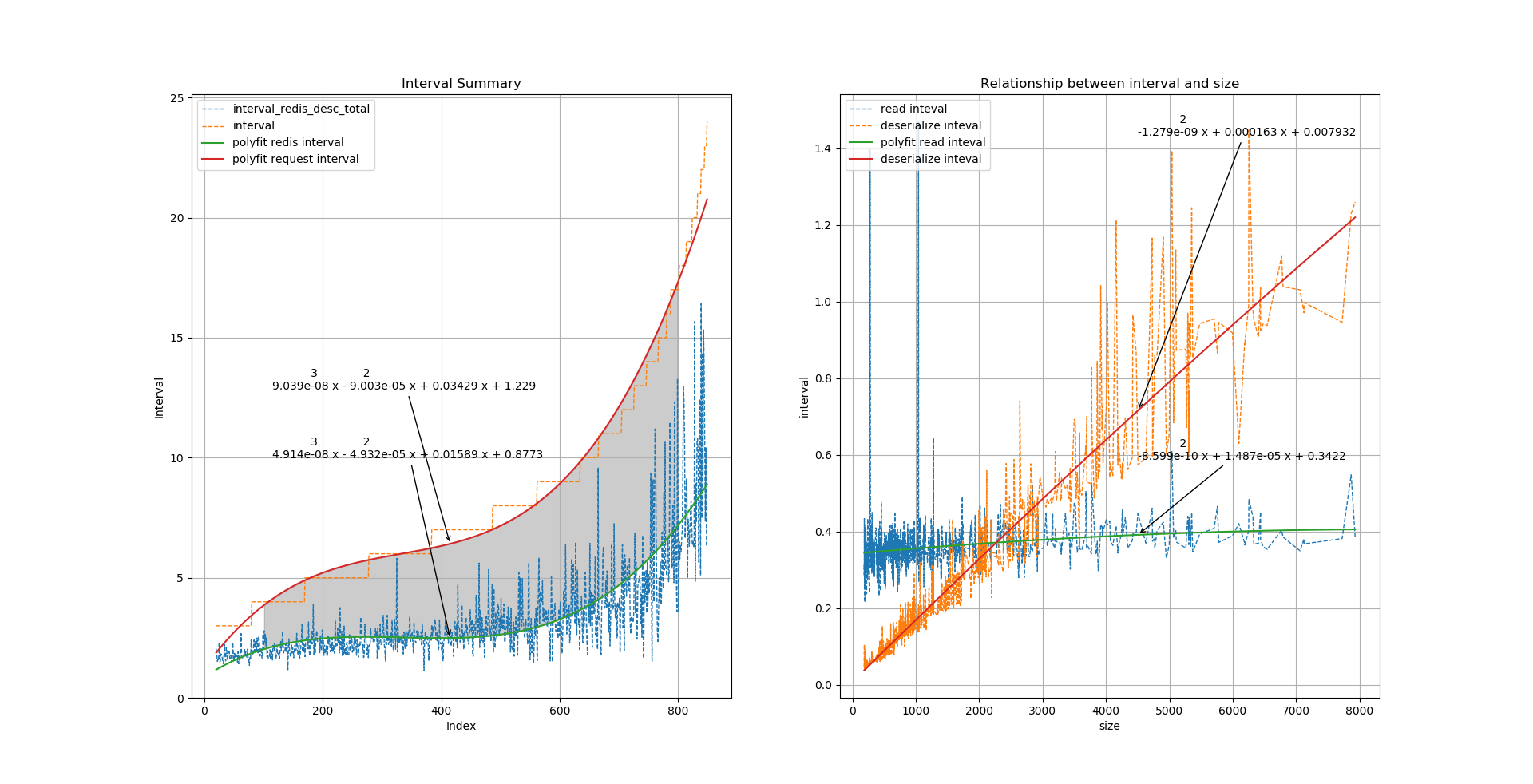
- 层级数据关联数据打包读取 – 访问合并 比如酒店信息和房型信息,酒店下面有很多房型,在读取酒店信息的同时将该酒店关联的房型信息一并读取,减少房型级别的多次读取耗时。如下实际数据分析:左图是请求耗时和处理Redis数据耗时(包括读取时间和反序列化时间),阴影是两者间的gap,当耗时增加时,其实处理Redis数据的影响将不断减小,这时应该考虑优化业务处理时间。右图为不同数据Size下读取和反序列化耗时,虚线为实际值,实线为拟合曲线,反序列化时间和读取时间同Size呈线性关系,但随着Size的增加,读取时间增加的较为平缓,所以合并读取减少读取次数有利于降低处理Redis数据的时间。