排序
排序是程序开发中一种非常常见的操作,对一组任意的数据元素(或记录)经过排序操作后,就可以把他们变成一组按关键字排序的有序队列。
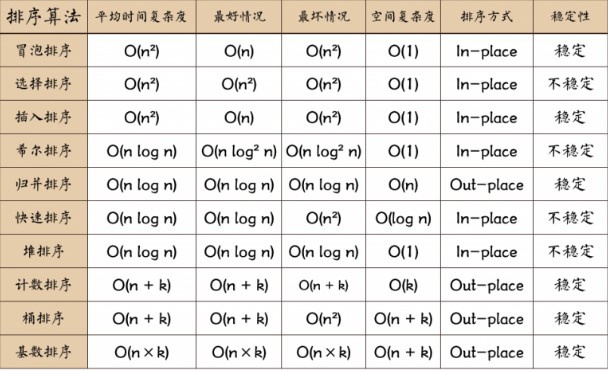
排序算法衡量指标
时间复杂度:它主要是分析关键字的比较次数和记录的移动次数。
空间复杂度:分析排序算法中需要多少辅助内存。
稳定性:若两个记录A和B的关键字值相等,但是排序后A,B的先后次序保持不变,则称这种排序算法是稳定的;反之,就是不稳定的。
常用的内部排序算法
- 选择排序(直接选择排序,堆排序)
- 交换排序(冒泡排序,快速排序)
- 插入排序(直接插入排序,折半插入排序,Shell排序)
- 归并排序
- 桶式排序
- 基数排序
排序算法的算法实现
直接选择排序
直接选择排序的基本操作:每一趟从待排序的数据元素中选出最小(或最大)的一个元素,顺序放在已排好序的数列的最后,直到全部待排序的数据元素排完,它需要经过n-1趟比较。算法不稳定,O(1)的额外的空间,比较的时间复杂度为O(n^2),交换的时间复杂度为O(n),并不是自适应的。在大多数情况下都不推荐使用。只有在希望减少交换次数的情况下可以用。
public static void SlectionSort(int[] data) {
int len = data.length;
int minindex = 0;// 记录最小值的索引
for (int i = 0; i < len; i++) {
minindex = i;
for (int j = i; j < len; j++) {
if (data[j] < data[minindex])
minindex = j;// 若后面元素小于最小值,将索引j赋值给minIndex
}
swap(data, i, minindex);
}
}
堆排序
堆排序是利用堆这种数据结构所设计的一种排序算法,可以利用数组的特点快速定位指定索引的元素。满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。堆排序是不稳定的排序方法,辅助空间为O(1), 最坏时间复杂度为O(nlogn) ,堆排序的堆序的平均性能较接近于最坏性能。
大根堆排序的基本思想:
- 先将初始文件R[1..n]建成一个大根堆,此堆为初始的无序区
- 再将关键字最大的记录R1和无序区的最后一个记录R[n]交换,由此得到新的无序区R[1..n-1]和有序区R[n],且满足R[1..n-1].keys≤R[n].key
- 由于交换后新的根R[1]可能违反堆性质,故应将当前无序区R[1..n-1]调整为堆。然后再次将R[1..n-1]中关键字最大的记录R[1]和该区间的最后一个记录R[n-1]交换,由此得到新的无序区R[1..n-2]和有序区R[n-1..n],且仍满足关系R[1..n-2].keys≤R[n-1..n].keys,同样要将R[1..n-2]调整为堆。
- ……
- 直到无序区只有一个元素为止。

public static void HeapSort(int[] array, int len) {
if (len > 0) {
createHeap(array, len - 1);
swap(array, 0, len - 1);
HeapSort(array, len - 1);
}
}
private static void createHeap(int[] data, int lastIndex) {
// TODO Auto-generated method stub
for (int i = (lastIndex - 1) / 2; i >= 0; i--) {
// 保存当前正在判断的结点索引
int root = i;
while (root * 2 + 1 <= lastIndex) {
int leftChild = 2 * root + 1;
int rightChild = 2 * root + 2;
if (leftChild < lastIndex) {
if (data[leftChild] < data[rightChild]) {
leftChild++;
}
}
if (data[leftChild] > data[i]) {
swap(data, i, leftChild);
root = leftChild;
} else {
break;
}
}
}
}
冒泡排序
排序过程:设想被排序的数组R[1..N]垂直竖立,将每个数据元素看作有重量的气泡,根据轻气泡不能在重气泡之下的原则,从下往上扫描数组R,凡扫描到违反本原则的轻气泡,就使其向上”漂浮”,如此反复进行,直至最后任何两个气泡都是轻者在上,重者在下为止。
public static void BubbleSort(int[] array){
int len = array.length;
for(int i=len-1;i>0;i--){
for(int j=0;j<i;j++){
if(array[j]>array[j+1])
swap(array,j,j+1);
}
}
}
private static void BubbleSort(int data[], int n){
int left = 0; // 初始化边界
int right = n - 1;
while (left < right){
for (int i = left; i < right; i++){
if (data[i] > data[i + 1]){
swap(data, i, i + 1);
}
}
right--;
for (int i = right; i > left; i--){
if (data[i - 1] > data[i]){
swap(data, i - 1, i);
}
}
left++;
}
}
快速排序
快速排序由C. A. R. Hoare在1962年提出。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
public static void QuickSort(int[] array,int lo,int hi){
if(lo>=hi) return;
int j=partition(array,lo,hi);
QuickSort(array,lo,j-1);
QuickSort(array,j+1,hi);
}
private static int partition(int[] array, int lo, int hi) {
// TODO Auto-generated method stub
int x=array[lo];
int i=lo;
int j=hi+1;
while(true){
while(array[++i]<x)
if(i==hi) break;
while(array[--j]>x)
if(j==lo) break;
if(i>=j) break;
swap(array,i,j);
}
swap(array,lo,j);
return j;
}
归并排序
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
算法描述如下:
- 把长度为n的输入序列分成两个长度为n/2的子序列;
- 对这两个子序列分别采用归并排序;
- 将两个排序好的子序列合并成一个最终的排序序列。
public static void MergeSort(int[] array, int left,int right){
if(left>=right) return;
int center = (left+right)/2;
MergeSort(array,left,center);
MergeSort(array,center+1,right);
Merge(array,left,center,right);
}
private static void Merge(int[] array, int left, int center, int right) {
// TODO Auto-generated method stub
int[] temp = Arrays.copyOf(array, array.length);
int lo=left;
int hi=center+1;
for(int i=left;i<=right;i++){
if(lo>center) array[i]=temp[hi++];
else if(hi>right) array[i]=temp[lo++];
else if(temp[lo]<temp[hi]) array[i]=temp[lo++];
else array[i]=temp[hi++];
}
}
插入排序
插入排序法,就是检查第i个数字,如果在它的左边的数字比它大,进行交换,这个动作一直继续下去,直到这个数字的左边数字比它还要小,就可以停止了。插入排序法主要的回圈有两个变数:i和j,每一次执行这个回圈,就会将第i个数字放到左边恰当的位置去。
算法描述如下:
- 从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前扫描
- 如果该元素(已排序)大于新元素,将该元素移到下一位置
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置后
- 重复步骤2~5
public static void InsertSort(int[] array){
if(array.length<2) return;
for(int i=1;i<array.length;i++){
int temp=array[i];
for(int j=i-1;j>=0;j--){
if(temp<array[j]){
array[j+1]=array[j];
array[j]=temp;
}else{
break;
}
}
}
}
折半插入排序
折半插入排序法,又称二分插入排序法,是直接插入排序法的改良版,采用二分查找法来减少比较操作的次数。
public static void HalfInsertSort(int[] array){
if(array.length<2) return;
for(int i=1;i<array.length;i++){
int temp = array[i];
int index = HalfSearch(array,0,i,temp);
for(int j=i-1;j>=index;j--){
array[j+1]=array[j];
array[j]=temp;
}
}
}
public static int HalfSearch(int[] array,int left,int right,int key){
int index = Arrays.binarySearch(array, left, right, key);
if(index<0){
return -(index+1);
}else
return index;
}
希尔排序
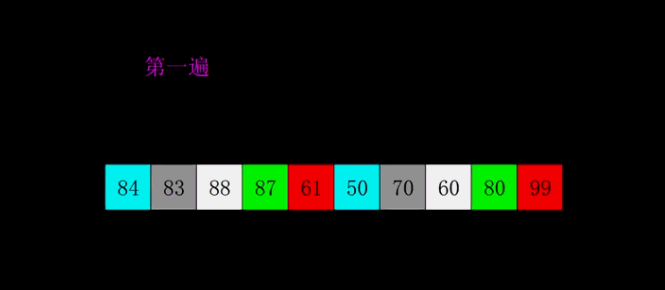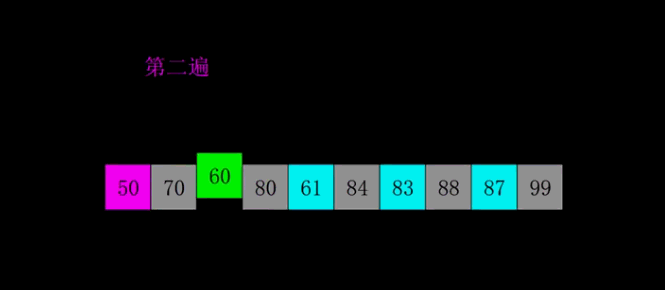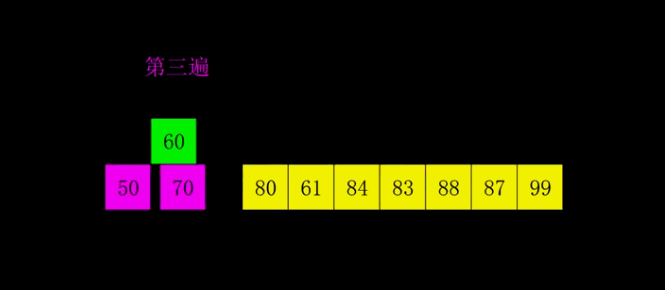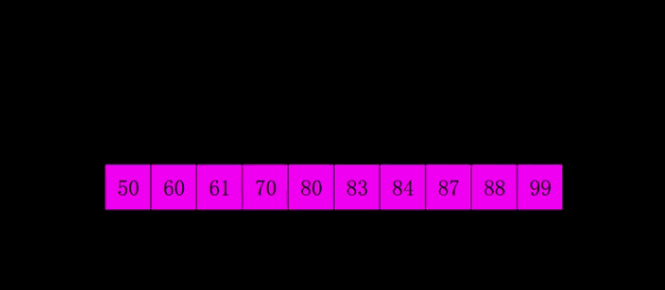
希尔排序(缩小增量法) 属于插入类排序,由Shell提出,希尔排序对直接插入排序进行了简单的改进:它通过加大插入排序中元素之间的间隔,并在这些有间隔的元素中进行插入排序,从而使数据项大跨度地移动,当这些数据项排过一趟序之后,希尔排序算法减小数据项的间隔再进行排序,依次进行下去,进行这些排序时的数据项之间的间隔被称为增量,习惯上用字母h来表示这个增量。 常用的h序列由Knuth提出,该序列从1开始,通过如下公式产生: h = 3 * h +1 反过来程序需要反向计算h序列,应该使用 h=(h-1)/3
public static void ShellSort(int[] array){
int len = array.length;
int h=1;
while(h<len/3) h=3*h+1;
while(h>=1){
for(int i=h;i<len;i++){
for(int j=i;j>=h&&array[j]<array[j-h];j=j-h){
swap(array,j-h,j);
}
}
h=h/3;
}
}
计数排序
计数排序的核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。
算法描述如下:
-
找出待排序的数组中最大和最小的元素;
-
统计数组中每个值为i的元素出现的次数,存入数组C的第i项;
-
对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加);
-
反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1。
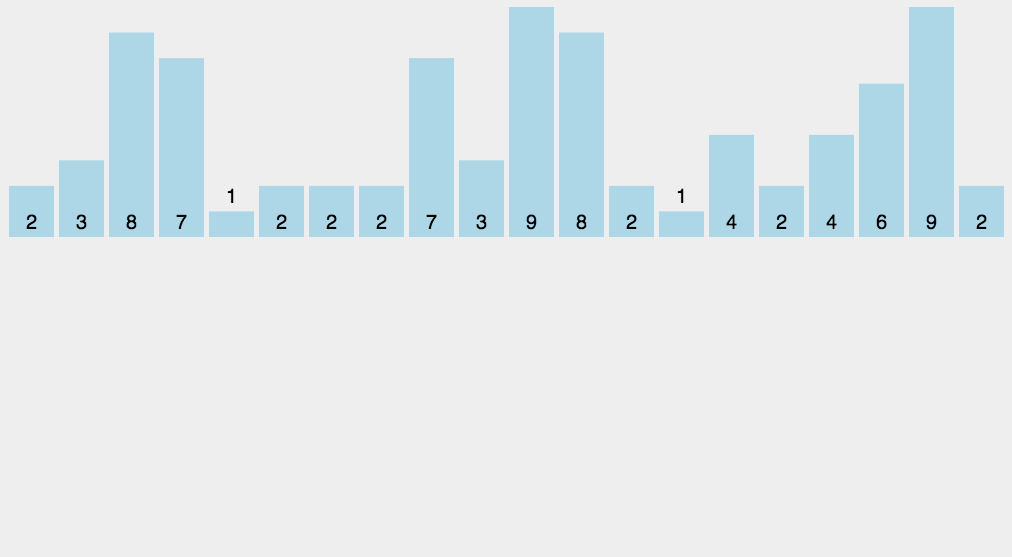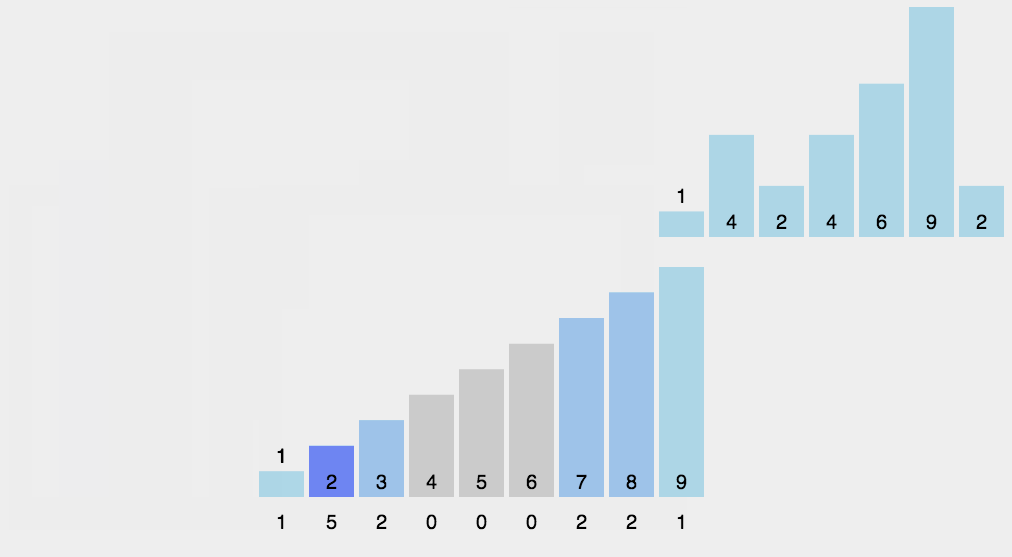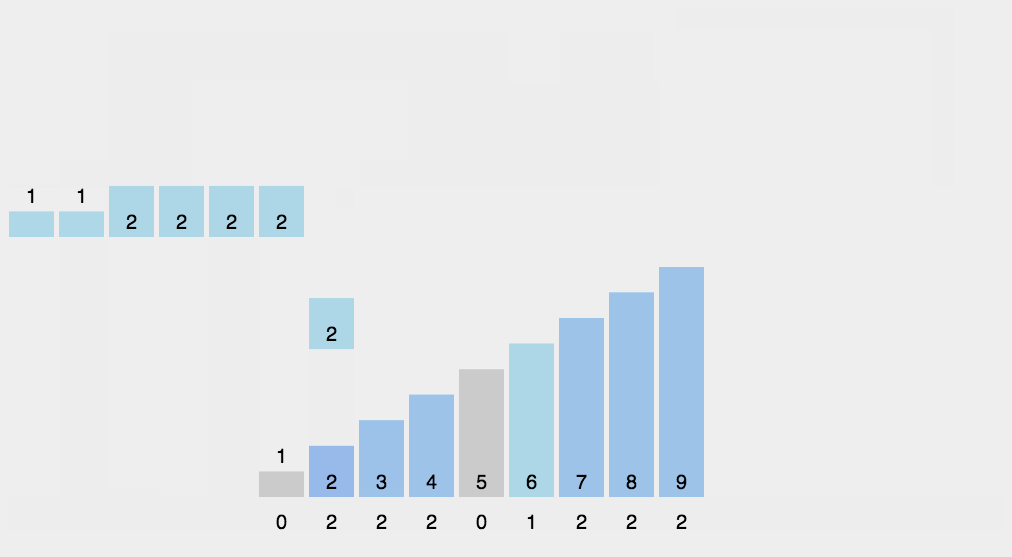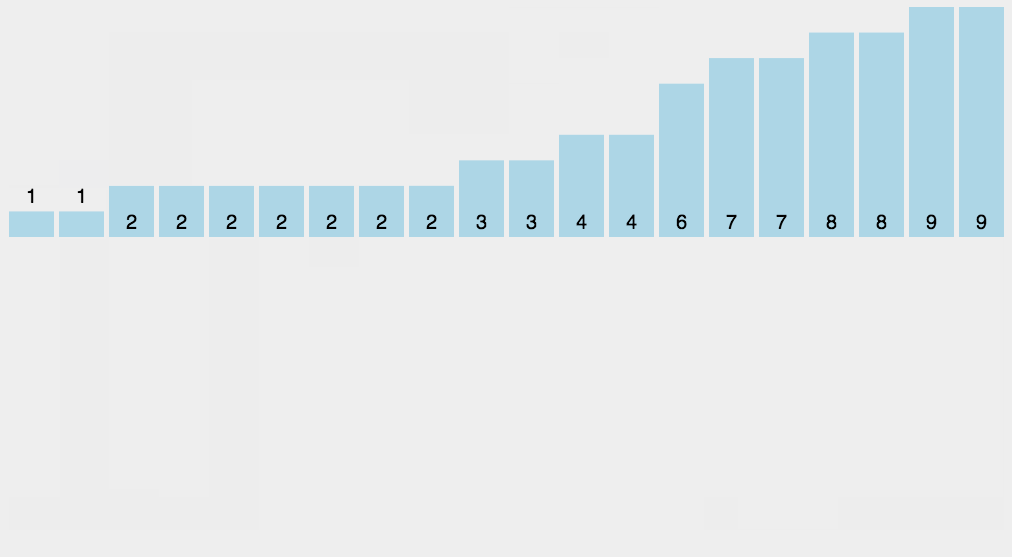
public static void CountSort(int[] array){
int len = array.length;
int[] temp = new int[len];
int[] count = new int[len+1];
int max=array[0];
int min=array[0];
for(int i=0;i<len;i++){
max = max>array[i]?max:array[i];
min = min<array[i]?min:array[i];
count[array[i]]++;
}
for(int i=min;i<max;i++){
count[i+1]=count[i+1]+count[i];
}
for(int k=len-1;k>=0;k--){
temp[count[array[k]]-1]=array[k];
count[array[k]]--;
}
for(int i=0;i<len;i++){
array[i]=temp[i];
}
}
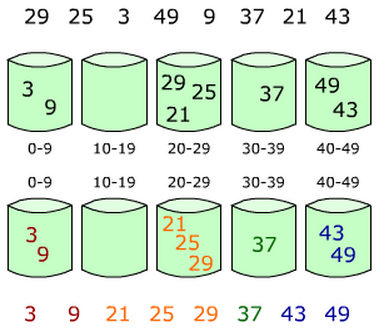
桶排序
桶排序 (Bucket sort)或所谓的箱排序,是一个排序算法,工作的原理是将数组分到有限数量的桶子里。每个桶子再个别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序)。桶排序是鸽巢排序的一种归纳结果。当要被排序的数组内的数值是均匀分配的时候,桶排序使用线性时间(Θ(n))。但桶排序并不是 比较排序,他不受到 O(n log n) 下限的影响。
public static void BucketSort(int[] array){
int max = array[0];
int min = array[0];
for(int i=0;i<array.length;i++){
max = Math.max(max,array[i]);
min = Math.min(min,array[i]);
}
int bucketNum = (max-min)/array.length+1;
ArrayList<ArrayList<Integer>> bucketList = new ArrayList<>(bucketNum);
for(int i=0;i<bucketNum;i++){
bucketList.add(new ArrayList<Integer>());
}
for(int i=0;i<array.length;i++){
int num = (array[i]-min) / (array.length);
bucketList.get(num).add(array[i]);
}
for(int i=0;i<bucketList.size();i++){
Collections.sort(bucketList.get(i));
}
int j=0;
for(int i=0;i<bucketNum;i++){
Iterator iter = bucketList.iterator();
while(iter.hasNext()){
array[j++] = iter.next();
}
}
}
基数排序
基数排序已经不再是一种常规的排序方式,它更多地像一种排序方法的应用,基数排序必须依赖于另外的排序方法。基数排序的总体思路就是将待排序数据拆分成多个关键字进行排序,也就是说,基数排序的实质是多关键字排序。
多关键字排序的思路是将待排数据里德排序关键字拆分成多个排序关键字;第1个排序关键字,第2个排序关键字,第3个排序关键字……然后,根据子关键字对待排序数据进行排序。 基数排序方法对任一子关键字排序时必须借助于另一种排序方法,而且这种排序方法必须是稳定的。 对于多关键字拆分出来的子关键字,它们一定位于0-9这个可枚举的范围内,这个范围不大,因此用桶式排序效率非常好。 对于多关键字排序来说,程序将待排数据拆分成多个子关键字后,对子关键字排序既可以使用桶式排序,也可以使用任何一种稳定的排序方法。 多关键字排序时有两种解决方案:
- 最高位优先法(MSD)(Most Significant Digit first)
- 最低位优先法(LSD)(Least Significant Digit first)

public static void radixSort(int[] data, int radix, int d) {
// 缓存数组
int[] tmp = new int[data.length];
int[] buckets = new int[radix];
for (int i = 0, rate = 1; i < d; i++) {
// 重置count数组,开始统计下一个关键字
Arrays.fill(buckets, 0);
// 将data中的元素完全复制到tmp数组中
System.arraycopy(data, 0, tmp, 0, data.length);
// 计算每个待排序数据的子关键字
for (int j = 0; j < data.length; j++) {
int subKey = (tmp[j] / rate) % radix;
buckets[subKey]++;
}
for (int j = 1; j < radix; j++) {
buckets[j] = buckets[j] + buckets[j - 1];
}
// 按子关键字对指定的数据进行排序
for (int m = data.length - 1; m >= 0; m--) {
int subKey = (tmp[m] / rate) % radix;
data[--buckets[subKey]] = tmp[m];
}
rate *= radix;
}
}
经典题目
Sort Colors
Given an array with n objects colored red, white or blue, sort them so that objects of the same color are adjacent, with the colors in the order red, white and blue. Here, we will use the integers 0, 1, and 2 to represent the color red, white, and blue respectively. Note: You are not suppose to use the library’s sort function for this problem.
class Solution {
public void sortColors(int[] nums) {
if(nums==null||nums.length==0) return;
int[] result = new int[3];
int[] temp = new int[nums.length];
for(int i=0;i<nums.length;i++){
result[nums[i]]++;
}
for(int i=1;i<result.length;i++){
result[i]+=result[i-1];
}
for(int i=0;i<nums.length;i++){
temp[--result[nums[i]]]=nums[i];
}
for(int i=0;i<nums.length;i++){
nums[i]=temp[i];
}
}
}
class Solution {
public void sortColors(int[] nums) {
int red = -1;
int white = -1;
int blue = -1;
for(int i = 0; i < nums.length; i++){
if(nums[i] == 0){
nums[++blue] = 2;
nums[++white] = 1;
nums[++red] = 0;
} else if(nums[i] == 1){
nums[++blue] = 2;
nums[++white] = 1;
} else{
nums[++blue] = 2;
}
}
}
}